When you enquire about availability of a service to cloud IaaS providers, without fail they talk about three nines (99.9%), four nines, five nines uptime percentages and design for failure ideas. The leading IaaS service Amazon EC2 offers a 99.95% of service commitment and that translates to 4.38 hours of downtime per year (or 5.04 minutes per week). Rackspace offers 100% network uptime guarantee!
Information – The above mentioned availability excludes scheduled downtime for maintenance apart from many other exclusions mentioned in mouse-print.

Although on any given day the cloud service availability is much higher than the traditional hosting service yet cloud IaaS has its own share of hiccups and that make them talk of the town as the expectations are very high. Every now and then we keep hearing about the outages of Amazon AWS, Microsoft or Google. As a result, in last few major outages the social media was all buzzing with the talks of unavailability of some popular cloud hosted services like Netflix,
Twitter, Zynga, Quora, Heroku, Instagram, AirBnB, Foursquare and Reddit etc. that went offline due to their service providers outages.
Outages are a part of IT and you can’t stop them
No matter how well prepared you are to prevent an outage; somehow it is waiting to happen! There are multiple components in hardware & software apart from multiple parameters that must collaborate seamlessly to run a service and anyone of them can fail at any point in time making the service unavailable. Additionally there are many external factors (natural disasters, grid failures etc.) that are out of control of anyone or any single entity. I think it is not wise to expect a service that is always available and 100% reliable.
But what about your customers?
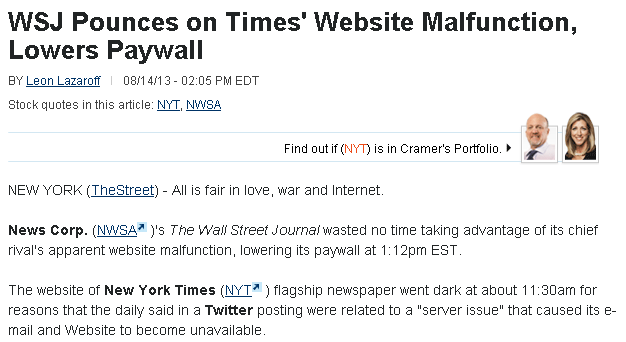
For every downtime you can easily play the tweet-and-blame your provider game, as many services are already doing, but eventually it’s you who has to bear the revenue loss apart from losing the competitive edge and the brand value of your company. Even a few minutes of downtime is blown out of proportion in social media circles. Also it seems, your competition is just waiting to grab this opportunity and turn it into an advantage, something like this:
How can IaaS minimize the effect of outages?
Existing solutions
1. Mirroring and Availability Zones: Rackspace and Amazon EC2
The IaaS providers indeed have some strategy for it. Rackspace offers multiple geographically separated regions and it recommends that by mirroring your infrastructure between datacenters you can mitigate outage risk. On the other hand, Amazon EC2 offers multiple AWS Availability Zones. As per Amazon’s portal FAQs:
Each availability zone runs on its own physically distinct, independent infrastructure, and is engineered to be highly reliable. Common points of failures like generators and cooling equipment are not shared across Availability Zones. Additionally, they are physically separate, such that even extremely uncommon disasters such as fires, tornados or flooding would only affect a single Availability Zone.
But it has been observed that during last year’s outage of Amazon EC2 (US East data center) on 22 Oct. 2012 even the applications configured for multiple availability zone were knocked off.
2. Multi-hypervisor design: Example OnApp Cloud
OnApp’s server based multi-hypervisor design monitors different cloud services and supports automatic failover by relocating virtual machines and rerouting application data. This service empowers you to point-click-and-manage clouds based on different virtualization platforms. OnApp currently supports Xen, KVM and VMware hypervisors.
3. Federated network of public cloud providers - Computenext and 6Fusion
Federation of cloud services (cloud brokerage) is about accessing multiple cloud IaaS from a single sign-on account and monitoring them apart from comparing, measuring and unified billing of the compute resources. Based on your requirements, you can change your provider if needed without rewriting your code and API calls. No more vendor lock-ins!
It seems the above mentioned platforms are already serving as the basis of the beginning of the much talked multi-cloud approach by providing the API abstraction (explained later) to the multi-cloud deployments. I think they should take their service to the next level by providing automatic failover and built-in real-time communication between multiple vendors. A formidable challenge!
Nextgen solution
Is Multi-cloud approach a better strategy to achieve highest possible service availability?
Yes, of course it is. A few companies have already started experimenting this (PayPal for instance). A few have already sensed the upcoming demand for it and are in the process of building right tools for multi-cloud approach (RightScale multi-cloud management). Apart from apparent benefit of high availability multi-cloud may lead to price reduction and healthy competition among IaaS providers for a better service. As a customer you no longer have to face that vendor-lock-in issue.
What are the challenges in multi-cloud implementation?
As a developer I understand that implementing this is easier said than done unless we address the following cloud standards issues:
Interoperability Portability etc.
The path to multi-cloud goes via APIs
APIs…? I won’t define APIs here but let me give you a practical scenario from daily life to make you understand the role of an API in a multi-cloud approach.
How do you book (reserve) flight tickets?
You simply sign in to your favorite travel portal (or the airline’s portal) and enter the journey date, city-pair detail, and within seconds you have a list of available airlines on your screen. You choose one of them and after a few clicks and within a few minutes you’ve got the booking confirmation message. Sounds so simple.
Now you must be aware that there are 1000s of travel portals, offering flight booking services to millions of direct customers (registered/guest users) and travel agents in almost 200 countries spread around the globe! Similarly for train and bus bookings, many of these portals are providing you with the facility to view seat layout and book as per your requirement. As booking are going on simultaneously across the world through 1000s of portals:
How do they ensure that the same seat is not booked for more than one customer or that the total number of bookings should not exceed the available seats? Now this sounds a bit complex, isn’t it?
All this is made possible via the magic of APIs running in the background
Airlines, train or bus operators has their inventory. They (or a third party) maintain a computer reservation system (CRS) where they enter their inventory details in their respective database. Once they have a CRS, every vendor who wants to be a part of GDS (Global Distribution System) needs to expose a web API to access its inventory. A GDS will aggregate many such APIs from different vendors and can offer its own web API to multiple channels like travel portals throughout the world.
Now, any booking request to the GDS API will be directed to all the participating vendors computer reservation system (CRS) and the response from them is consolidated and shown to the calling program, (i.e. to your favorite travel portal). So, the GDS APIs are simply a layer of abstraction between the actual vendor inventory and the consumer (travel portals). More or less this is the work flow in any ticket booking system.
To simplify the above let me say that if you wish to develop a travel portal you don’t need to worry about talking to the multiple operators for inventory. You can contact a GDS provider, (Galileo, Amadeus, Sabre etc.) purchase a license and integrate their API in your web application. The API will receive a few parameters like date, city-pair etc. from your portal and will respond with the availability and fare details.
So, if you want to build a travel portal for international flight booking, it doesn’t matter in which part of the globe you are, as a prerequisite you have to integrate the GDS APIs to your application. This abstraction, to some extent lowers the barrier of developing a portal and that’s the reason there are numerous new travel portals starting up operation every other day.
Bottom-line
I think the above analogy says it all for the cloud services as well. The IaaS providers have got an inventory to share and most of them already have their own APIs to manage server resources. But before the IaaS goes the multi-cloud way on an industrial scale many rough patches need to be smoothened. May be the cloud should evolve and mature a little more in terms of interoperability and standards to offer this much awaited new approach at an affordable cost. What do you think… are we going to witness many multi-cloud implementations in 2014?
